Entering hundreds of lines into any program by hand is not the most satisfying work and a waste of time, if you consider the fact that Excel or other spreadsheet programs could reduce that time drastically.
You are not able to copy and paste multiple lines into a DMN while editing it with the Camunda Modeler.
Imagine that your coworker provides you with a nice excel sheet with hundreds of rows and your task would be to create a DMN table out of it. Without our converter, your only choice is to enter the lines by hand, and this might take very long.
We developed a tool that helps you out with creating DMN models from scratch and editing already existing ones with the help of a table in any spreadsheet tool you like.
Let me show you what you need and how it works.
Basically there are 4 things you need for converting a CSV file into a DMN table.
- 1. Our converter (https://github.com/jit-open/CsvToDmnConverter)
- 2. Java 8 or higher installed on your computer
- 3. Maven installed on your computer
- 4. CSV-file in a specific format
The right format of your CSV is very important. The following table structure shows you the format, in which you will have to enter the data into your spreadsheet program, before exporting it as a csv.
The DMN rules start in row 5. Row 1-4 contain mandatory configuration. More information on how to configure the table or the meaning of each value in it, is contained in the readme.md file of the git repository. (https://github.com/jit-open/CsvToDmnConverter)
Basically the format is like following:
| . | A | B | C | D | E | F | G |
| 1 | DmnId | Title | Hit Policy | ||||
| 2 | Input | Input | Input | Output | Output | ||
| 3 | ColName1 | ColName2 | ColName3 | ColName4 | ColName5 | ||
| 4 | string | integer | boolean | string | integer | ||
| 5 | SomeStr | SomeInt | true | SomeStr | SomeInt | Comment | |
| 6 |
Now a small example.
Your CSV-File (values separated with comma) should look like this (further explanation in the Readme.md file which can be found in the repository):
Then on your .jar file in your target folder, which you got from compiling it with Maven run this command:

Your outcome should be following:
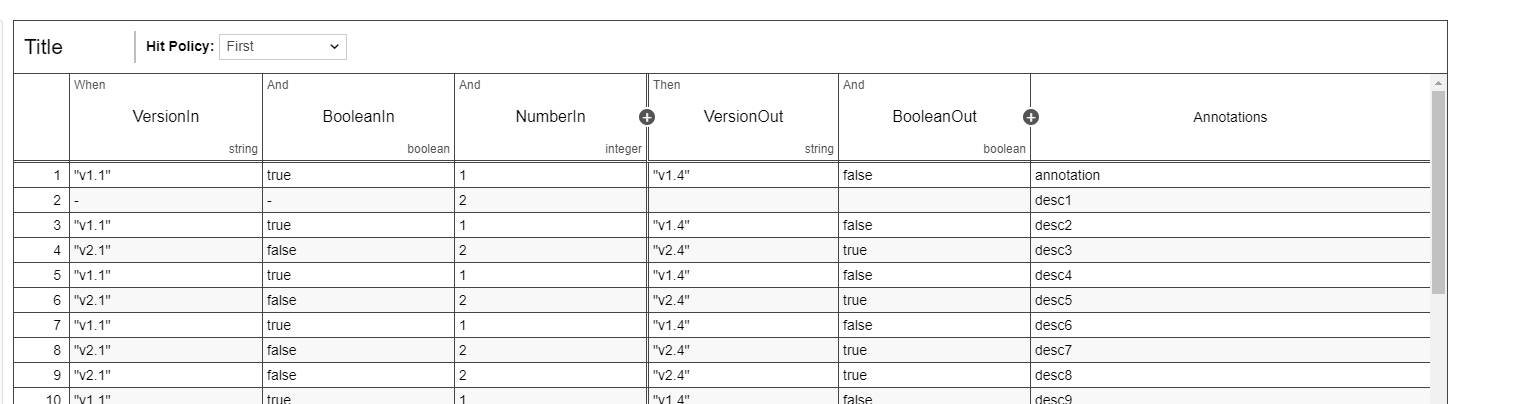
The converter is a nice tool to have.
Although you can’t set any detailed column information, because the csv file format would have been too complex to create, you can easily set this information in the Camunda Modeler afterwards.
Despite that, it will take much work off of your shoulders and it will bring many more advantages with it e.g. if you want to use spreadsheet functions with DMN diagrams, enter information to a DMN you have in a table and many others.
The fact that it allows you to convert an existing DMN to a CSV file opens many other doors, like editing already existing DMN files with a spreadsheet tool or helping you copy information for documentation purposes.
Please feel free to take a look at the repository the code is published in: https://github.com/jit-open/CsvToDmnConverter
A more detailed technical documentation and explanation of the CsvToDmnConverter can be found in the Readme-file of the public git repository.
Written by Clemens Zumpf
JIT Developer
Photo by Mika Baumeister on Unsplash



