
Kafka is a great instrument. It is widely used in event-driven architectures, and it does the job perfectly fine. However, this is not the only use-case for it. Kafka is also very well suitable for data replication and ingestion use-cases, as well as for building modern ETL or ELT pipelines. The most noteworthy reasons for that are that Kafka is fast, stores data efficiently, and can be integrated with almost any imaginable data source, including APIs, file systems, SQL and NoSQL databases and big data solutions, such as Elastic Search, HDFS, and so on.
Usually, it is recommended to use Kafka Connect for such integrations, especially when it comes to integrations with databases. But in fact you are not limited here, and there is more than one way of doing it.
In this blog post, we invite you to overview some of the possible ways to integrate Kafka with relational databases, which is claimed to be one of the most common types of integrations.
Why would I need it?
Let’s imagine that you have many different databases, which store contexts of different applications or microservices in your ecosystem. Sooner or later you undestand that the contexts of the applications must be in sync. For example, customers data should usually be available for most of them. Hence, now you need a way to replicate your data between apps databases.
Or, you may need to implement some reporting solution, which also requires data from many different sources, probably in depersonalized, or aggregated fasion. Ideally, you would need the transformations to be done “on-the-fly”. Well, this is also what can be easily done by Kafka with some additional components, such as Kafka Streams or ksqlDB.
But before going deeper into that, it is important to clearly understand data organization options and decide on one, which is the most suitable in your particular situation.
Data organization options
In almost every relatively big distributed system there are many different applications, which master different types of data. And in most cases, when a new business case appears, only some subset of application data is needed to be available for a target system for this particular case. This generally leaves us with the three options, if the target system is not mastering the needed data:
- Option 1. Source Side Transformations – in this case, you prepare the needed subset of data on the source side, and expose only the subset of data to Kafka and then replicate it to the target system.
- Option 2. Kafka Transformations – here you expose the whole entity or entities from the source system to Kafka, within which the needed subset of data is maintained. Then, you make necessary filtrations and transformations inside Kafka itself, using Kafka Streams or ksqlDB. In such a way, you prepare data for consumption in a new Kafka topic with only that data, which is relevant for the given business case, and then replicate data from it directly to the target system.
- Option 3. Target Side Transformations – when you can afford to “duplicate” data in your systems, or you need the whole dataset to be available in the target system (for instance, in a data warehouse or a data lake), you may expose it to Kafka in full from the source system. The data subset, relevant for your current business case, will be included as well, so you do not have to worry about it. Finally, you transfer it, now maintained by Kafka, to the target system „as is“, which means without any logical transformations or aggregations (only technical transformations aka data serialization may be applied). In the end, you have all the data in your target system, and you can extract the needed subset from it whenever you want.
All three approaches have their pros and cons, and they can even be used and mixed together. However, by mixing approaches, some of their benefits could be lost. But what if we try to compare them and try to find some benefits and drawbacks of each?

As mentioned above it is also possible to mix the approaches. For example, Option 2 can be mixed with Option 3, when the source system is mastering some big dataset, which is exposed to Kafka in the whole. Then, it can be divided into some subclasses in Kafka and new derivative topics are created (i.e. a subset of customers data, relevant to the B2C sector and the other one to the B2B sector). Then, only the needed portion of data can be replicated to a target system. And different target systems can consume different subsets of data, derived from the same bigger entity.
How about we start already?
But enough of this foreword, and let’s assume you know how to organize your data optimally in your systems.
When we speak of actual Kafka integrations with databases, usually we mean one of these two integrations types from the database side:
- As a Source – the data is read from source database tables and is written into target Kafka topics
- As a Sink – the data is read from source Kafka topics and is written into a number of target database tables
And there is more than one way to implement either of them. The more or less standard way would be to use Kafka Connect Source or Sink connectors correspondingly, but you may as well implement your own Data Poller application, which would leverage Kafka Producer or Consumer Java API. There are also different Thirt Party solutions for importing data to Kafka or exporting it from there, for instance, Qlik Replicate, or IBM Infosphere Data Replication platform.
If we try to put all these components in the Kafka ecosystem, we would end up with something like this:

Diagram URL: follow me
Kafka Connect
Kafka Connect is an additional layer of abstraction between Kafka and external data sources. Kafka Connect cluster consists of one or more worker nodes. Each worker provides a RESTful API for you to manage connectors within them. When you instantiate a connector, one or more tasks are started for it. You, as a developer, may use any worker for your API calls – connectors and their tasks are balanced between worker nodes automatically and you do not have to worry about this. And this is why Kafka Connect is so cool – it is a self-balancing, scalable, centralized and declarative way to define your integrations. And it syncs the changes in near real-time, which makes it significantly different to traditional batch syncs.
Which connectors are available?
There are two main connector types – source and sink. Source connectors implement a protocol to retrieve data from an external data source, capture data changes (in other words, they implement CDC), and propagate these changes to Kafka topics as new records.
Sink connectors do the opposite job – whenever new records are written to monitored Kafka topics, the connector captures them, reads them from the topics, serializes and finally sends the new data to an external data source.
There are loads of already existing connectors. Many of them are available for download and installation through Confluent Hub, but you can as well find them on GitHub or on different corporative websites.
Connectors can be split into different categories by vendors or by license. There are official connectors, which are developed and supported by Confluent. For instance, Confluent JDBC Connectors (Source and Sink), which can be used with every JDBC supported database. They are universal, but have some functionality limitations, especially when it comes to the Source connector.
But, there are third-party companies, which also develop and support very useful connectors stacks. One of the most noteworthy examples is Red Hat inc. with their Debezium platform, which includes Source connectors for the most common database management systems, and these connectors leverage very efficient ways to retrieve data changes from the monitored tables.
Besides, you can find many community developed connectors, when it comes to some more exotic data source, or you can always extend an existing connector, or implement your own from scratch. However, this might be not an easy task.
It is also important to mention that many connectors are free, but there are some, which are commercially licenced. However, all of them have an evaluation period or are free to use in development environments with a single broker node setup. Nevertheless, do not forget to check the license conditions before sticking to a particular one.
Connector VS Connector Instance
The connector itself is just a Java Plugin library, which can be downloaded from the web and is installed cluster-wise. But to create your integration, you need to instantaniate it. To do so, you should compose a particular connector configuration, and deploy it to any of your Kafka Connect worker nodes.
Connector config contains such things as database connection details, database tables to be used, Kafka topic names, converters and single message tranformation properties. If you operate your Kafka Connect cluster in distributed mode, your connectors configs would be JSON files containing all this information.
After you compose your connector config, you deploy it using Kafka Connect RESTful API, and your connector instance is being created. Providing the config is correct, and the connector plugin library exists in the cluster, you will see your pipeline working after this step.
This makes this approach declarative and no-code, which is often highly desired, since people from your database department hardly ever speak native Java.
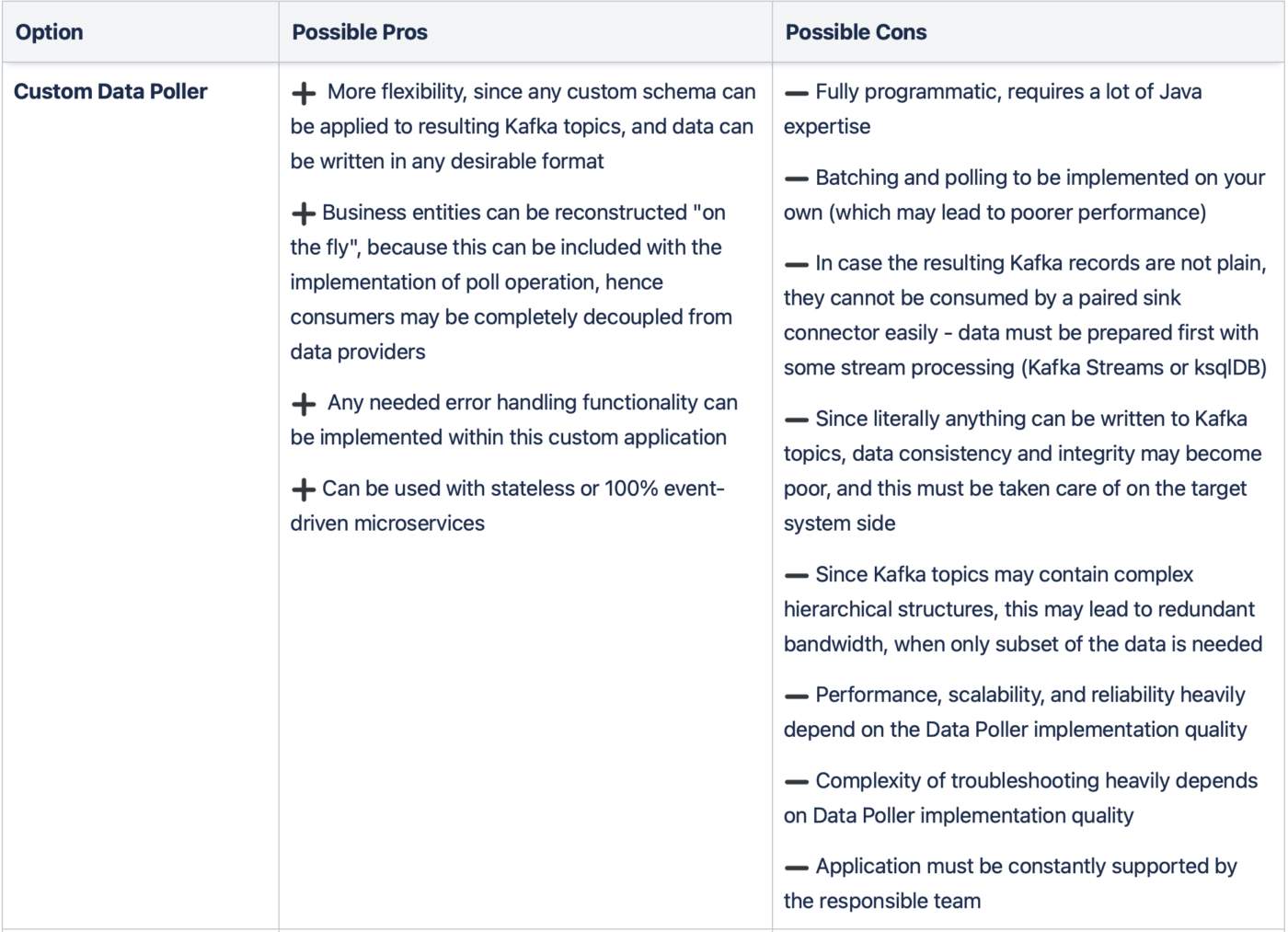
Low-level Data Poller
The second option would be to implement your own Data Poller application in Java or another programming language leveraging provided Producer or Consumer APIs. This approach is much more programmatic and may seem tempting, especially when you already have Java expertise in your team. It is also most the flexible approach when you decide to do it this way – you can implement literally any logic in your application between the database and the Kafka cluster, which is sometimes very hard to be done with Kafka Connect. However, such fundamental things as efficient batching and polling of the changed data implementation will be completely on your shoulders as well.
You should also be very careful here, because it is easy to find yourself overwhelmed over time, when you have many different integrations, and you have to maintain and monitor them all separately. Also, you have to implement your own CDC, when it comes to sourcing data from your databases to Kafka, which may be quite complex depending on a use case.
Third Party Solution
Another way would be to go for a third-party solution, such as Qlik Replicate or IBM Infosphere Data Replication platform. They may provide you with all the necessary functionality and even more. However, such platforms may have both benefits and drawbacks. For instance, “ready to market” solutions are usually bullet-proof tested and have very user-friendly interfaces, but on the other hand they often have functionality, which you will never use, but will have to pay for.
I personally did not test them for real world scenarios, and cannot tell you much about my experience with them, but they are definitely worth mentioning here.


Conclusion
There are no wrong ways on how to do your integrations between Kafka and databases. All of them have their strengths and weaknesses, but in fact, you are free to use and even combine any of them.
What you should do, however, is estimate your particular use cases for Kafka and the pipelines, which you are going to handle using it. You also should always keep in mind your team expertise, when you approach Kafka each time for the data replication use-case. Providing you do this properly, you will always make the right choice. Be brave and may the force be with you!
Useful Links:
More about JIT and our services: JIT Services
Written by Denis Savenko
Developer at JIT IT-Dienstleistungs Gesmbh
Photo by Boitumelo Phetla on Unsplash


